Linear code
In coding theory, a linear code is an error-correcting code for which any linear combination of codewords is also a codeword. Linear codes are traditionally partitioned into block codes and convolutional codes, although Turbo codes can be seen as a hybrid of these two types.[1] Linear codes allow for more efficient encoding and decoding algorithms than other codes (cf. syndrome decoding).
Linear codes are used in forward error correction and are applied in methods for transmitting symbols (e.g., bits) on a communications channel so that, if errors occur in the communication, some errors can be corrected or detected by the recipient of a message block. The codewords in a linear block code are blocks of symbols which are encoded using more symbols than the original value to be sent. A linear code of length n transmits blocks containing n symbols. For example, the [7,4,3] Hamming code is a linear binary code which represents 4-bit messages using 7-bit codewords. Two distinct codewords differ in at least three bits. As a consequence, up to two errors per codeword can be detected and a single error can be corrected.[2] This code contains 24=16 codewords.
Contents |
Definition and parameters
A linear code of length n and rank k is a linear subspace C with dimension k of the vector space 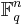 where
where 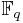 is the finite field with q elements. Such a code is called a q-ary code. If q = 2 or q = 3, the code is described as a binary code, or a ternary code respectively. The vectors in C are called codewords. The size of a code is the number of codewords and equals qk.
is the finite field with q elements. Such a code is called a q-ary code. If q = 2 or q = 3, the code is described as a binary code, or a ternary code respectively. The vectors in C are called codewords. The size of a code is the number of codewords and equals qk.
The weight of a codeword is the number of its elements that are nonzero and the distance between two codewords is the Hamming distance between them, that is, the number of elements in which they differ. The distance d of a code is minimum weight of its nonzero codewords, or equivalently, the minimum distance between distinct codewords. A linear code of length n, dimension k, and distance d is called an [n,k,d] code.
Remark: We want to give the usual standard basis because each coordinate represents a "bit" which is transmitted across a "noisy channel" with some small probability of transmission error (a binary symmetric channel). If some other basis is used then this model cannot be used and the Hamming metric does not measure the number of errors in transmission, as we want it to.
Properties
As a linear subspace of , the entire code C (which may be very large) may be represented as the span of a minimal set of codewords (known as a basis in linear algebra). These basis codewords are often collated in the rows of a matrix G known as a generating matrix for the code C. When G has the block matrix form 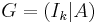 , where
, where 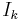 denotes the
denotes the 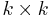 identity matrix and A is some
identity matrix and A is some 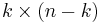 matrix, then we say G is in standard form.
matrix, then we say G is in standard form.
A matrix H representing a linear function 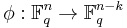 whose kernel is C is called a check matrix of C (or sometimes a parity check matrix). Equivalently, H is a matrix whose null space is C. If C is a code with a generating matrix G in standard form, G = (Ik | A), then H = (−At | In − k) is a check matrix for C. The code generated by H is called the dual code of C.
whose kernel is C is called a check matrix of C (or sometimes a parity check matrix). Equivalently, H is a matrix whose null space is C. If C is a code with a generating matrix G in standard form, G = (Ik | A), then H = (−At | In − k) is a check matrix for C. The code generated by H is called the dual code of C.
Linearity guarantees that the minimum Hamming distance d between a codeword c0 and any of the other codewords c ≠ c0 is independent of c0. This follows from the property that the difference c − c0 of two codewords in C is also a codeword (i.e., an element of the subspace C), and the property that d(c, c0) = d(c − c0, 0). These properties imply that
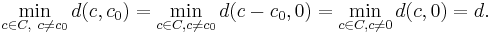
In other words, in order to find out the minimum distance between the codewords of a linear code, one would only need to look at the non-zero codewords. The non-zero codeword with the smallest weight has then the minimum distance to the zero codeword, and hence determines the minimum distance of the code.
The distance d of a linear code C also equals the minimum number of linearly dependent columns of the check matrix H.
Proof: Because 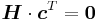 , which is equivalent to
, which is equivalent to 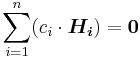 , where
, where  is the
is the  column of
column of 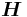 . Remove those items with
. Remove those items with 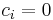 , those with
, those with 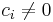 are linearly dependent. Therefore
are linearly dependent. Therefore 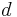 is at least the minimum number of linearly dependent columns. On another hand, consider the minimum set of linearly dependent columns
is at least the minimum number of linearly dependent columns. On another hand, consider the minimum set of linearly dependent columns 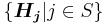 where
where 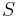 is the column index set.
is the column index set. 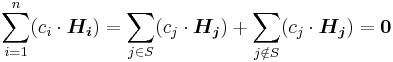 . Now consider the vector
. Now consider the vector 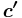 such that
such that 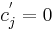 if
if 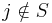 . Note
. Note 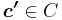 because
because 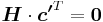 . Therefore we have
. Therefore we have 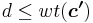 , which is the minimum number of linearly dependent columns in . The claimed property is therefore proved.
, which is the minimum number of linearly dependent columns in . The claimed property is therefore proved.
Example: Hamming codes
As the first class of linear codes developed for error correction purpose, the Hamming codes has been widely used in digital communication systems. For any positive integer 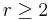 , there exists a
, there exists a ![[2^r-1, 2^r-r-1,3]_2](/2012-wikipedia_en_all_nopic_01_2012/I/a49fc5cc1f69a0e6c831b34d654a59a8.png) Hamming code. Since
Hamming code. Since 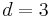 , this Hamming code can correct 1-bit error.
, this Hamming code can correct 1-bit error.
Example : The linear block code with the following generator matrix and parity check matrix is a ![[7,4,3]_2](/2012-wikipedia_en_all_nopic_01_2012/I/e4d0d4aefac6c4060622830e99cee510.png) Hamming code.
Hamming code.
 :
: 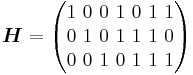
Example: Hadamard codes
Hadamard code is a ![[2^r, r, 2^{r-1}]_2](/2012-wikipedia_en_all_nopic_01_2012/I/03f12f36d182b57d5352f05c5b3e84e4.png) linear code and is capable of correcting many errors. Hadamard code could be constructed column by column : the
linear code and is capable of correcting many errors. Hadamard code could be constructed column by column : the 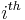 column is the bits of the binary representation of integer
column is the bits of the binary representation of integer  , as shown in the following example. Hadamard code has minimum distance
, as shown in the following example. Hadamard code has minimum distance 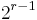 and therefore can correct
and therefore can correct 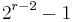 errors.
errors.
Example : The linear block code with the following generator matrix is a ![[8,3,4]_2](/2012-wikipedia_en_all_nopic_01_2012/I/2700bb37d02fc0ca8c58e6c744e98072.png) Hadamard code:
Hadamard code:  .
.
Hadamard code is a special case of Reed-Muller code If we take the first column (the all-zero column) out from 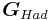 , we get
, we get ![[7,3,4]_2](/2012-wikipedia_en_all_nopic_01_2012/I/01ac96dd01b77bbff5f2b759b34a8b92.png) simplex code, which is the dual code of Hamming code.
simplex code, which is the dual code of Hamming code.
Nearest neighbor algorithm
The parameter d is closely related to the error correcting ability of the code. The following construction/algorithm illustrates this (called the nearest neighbor decoding algorithm):
Input: A "received vector" v in .
Output: A codeword w in C closest to v.
- Enumerate the elements of the ball of (Hamming) radius t around the received word v, denoted Bt(v).
- For each w in Bt(v), check if w in C. If so, return w as the solution!
- Fail when enumeration is complete and no solution has been found.
Note: "fail" is not returned unless t > (d − 1)/2. We say that a linear C is t-error correcting if there is at most one codeword in Bt(v), for each v in .
Popular notation
Codes in general are often denoted by the letter C, and a code of length n and of rank k (i.e., having k code words in its basis and k rows in its generating matrix) is generally referred to as an (n, k) code. Linear block codes are frequently denoted as [n, k, d] codes, where d refers to the code's minimum Hamming distance between any two code words.
Remark. The [n, k, d] notation should not be confused with the (n, M, d) notation used to denote a non-linear code of length n, size M (i.e., having M code words), and minimum Hamming distance d.
Singleton bound
Lemma (Singleton bound): Every linear [n,k,d] code C satisfies 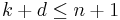 .
.
A code C whose parameters satisfy k+d=n+1 is called maximum distance separable or MDS. Such codes, when they exist, are in some sense best possible.
If C1 and C2 are two codes of length n and if there is a permutation p in the symmetric group Sn for which (c1,...,cn) in C1 if and only if (cp(1),...,cp(n)) in C2, then we say C1 and C2 are permutation equivalent. In more generality, if there is an 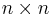 monomial matrix
monomial matrix 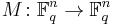 which sends C1 isomorphically to C2 then we say C1 and C2 are equivalent.
which sends C1 isomorphically to C2 then we say C1 and C2 are equivalent.
Lemma: Any linear code is permutation equivalent to a code which is in standard form.
Examples
Some examples of linear codes include:
- Repetition codes
- Parity codes
- Cyclic codes
- Hamming codes
- Golay code, both the binary and ternary versions
- Polynomial codes, of which BCH codes are an example
- Reed–Solomon codes
- Reed–Muller codes
- Goppa codes
- Low-density parity-check codes
- Expander codes
- Multidimensional parity-check codes
See also
Notes
- ^ William E. Ryan and Shu Lin (2009). Channel Codes: Classical and Modern. Cambridge University Press. p. 4. ISBN 978-0-521-84868-8.
- ^ Thomas M. Cover and Joy A. Thomas (1991). Elements of Information Theory. John Wiley & Sons, Inc. pp. 210–211. ISBN 0-471-06259-5.
External links
- q-ary code generator program
- Compute parameters of linear codes – an on-line interface for generating and computing parameters (e.g. minimum distance, covering radius) of linear error-correcting codes.
- Code Tables: Bounds on the parameters of various types of codes, IAKS, Fakultät für Informatik, Universität Karlsruhe (TH)]. Online, up to date table of the optimal binary codes, includes non-binary codes.